AWS ETL Pipeline for YouTube Data Analytics
Build a Serverless Data Lake with AWS Glue, Lambda, Athena & QuickSight
📊 Data Engineering: A complete serverless ETL pipeline that processes YouTube trending video statistics from multiple regions using a medallion architecture (raw → cleansed → analytics).
Architecture Diagram
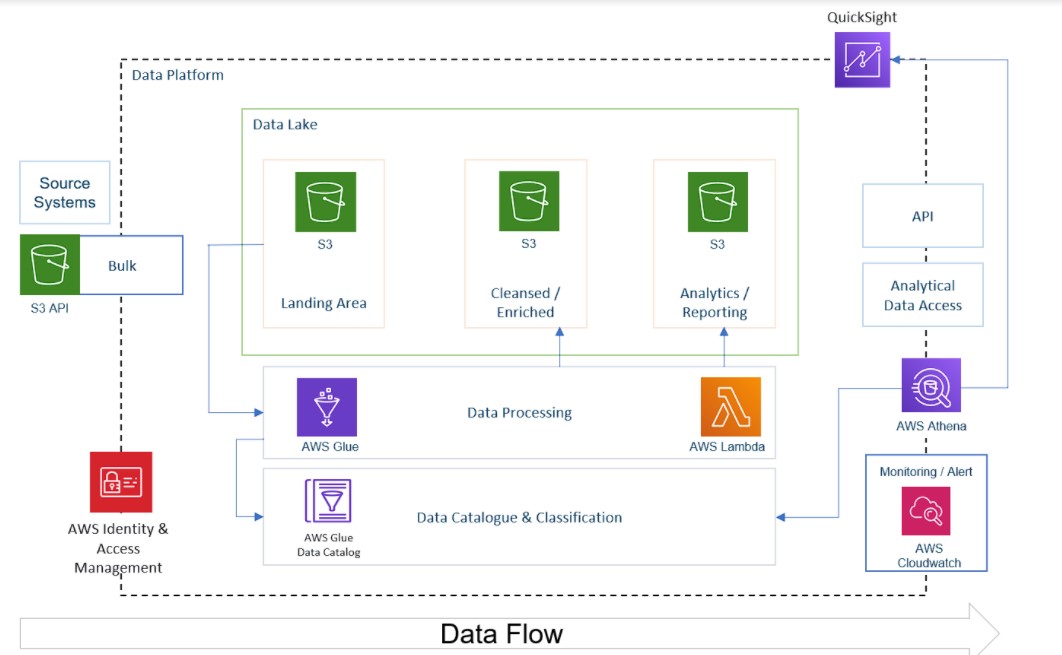
Raw Data (S3) → Lambda → Cleansed Layer (S3) → Glue ETL → Analytics Layer (S3) → Athena/QuickSightOverview
This project implements a complete serverless ETL pipeline on AWS to process and analyze YouTube trending video statistics data from multiple regions. The pipeline leverages AWS managed services to build a scalable, cost-effective data analytics solution following the medallion architecture pattern.
🎯 What I built: A data lake solution that ingests raw YouTube statistics (CSV & JSON), processes them through Lambda and Glue ETL jobs, and makes the data queryable via Athena and visualizable in QuickSight — all serverless.
Tech Stack
Storage
- Amazon S3 (Data Lake)
- Hive-style Partitioning
- Parquet Format
Processing
- AWS Lambda
- AWS Glue (PySpark)
- AWS Data Wrangler
Catalog & Query
- Glue Data Catalog
- Glue Crawler
- Amazon Athena
Analytics
- Amazon QuickSight
- Python / PySpark
- Pandas
Data Flow Workflow
1. Data Ingestion Layer
Raw CSV and JSON data files are uploaded to the S3 raw bucket. Data is organized using Hive-style partitioning (region=ca/, region=us/, etc.) supporting 10 regions: CA, DE, FR, GB, IN, JP, KR, MX, RU, US.
2. Data Processing Layer
A Lambda function is triggered by S3 events when JSON files are uploaded. It:
- Reads JSON data using AWS Data Wrangler
- Normalizes nested JSON structures with pandas
- Converts to Parquet format for optimized storage
- Registers data in the Glue Data Catalog
3. Data Transformation Layer
Glue ETL Jobs (PySpark-based) handle heavy transformations:
- Schema mapping and data type conversions
- Data quality resolution (null fields, type conflicts)
- Regional partitioning for efficient querying
- Predicate pushdown for query optimization
4. Data Analytics Layer
Transformed data is stored in Parquet format, partitioned by region, queryable via Amazon Athena, and visualized using Amazon QuickSight dashboards.
Key Features
- Event-driven Processing: Lambda automatically triggered on S3 uploads — no polling or scheduling needed
- Medallion Architecture: Three-layer data lake (raw → cleansed → analytics) for progressive data refinement
- Predicate Pushdown: Filters data at the source level to reduce transfer and processing time
- 75% Storage Reduction: Parquet columnar format vs CSV for compression and fast queries
- Multi-Region Support: Processes trending data from 10 countries with partition pruning
- Serverless: Zero infrastructure management — Lambda, Glue, Athena are all fully managed
Setup Instructions
1. Prerequisites
- AWS Account with appropriate IAM permissions
- AWS CLI configured with credentials
- Python 3.8+
- Basic understanding of S3, Lambda, Glue, and Athena
2. Clone the Repository
git clone https://github.com/upper-stack/aws-youtube-etl-pipeline.git
cd aws-youtube-etl-pipeline3. Create S3 Buckets
# Raw bucket
s3://bigdata-on-youtube-raw-{region}-{account-id}-{env}/
# Cleansed bucket
s3://bigdata-on-youtube-cleansed-{region}-{account-id}-{env}/
# Analytics bucket
s3://bigdata-on-youtube-analytics-{region}-{account-id}-{env}/4. Upload Raw Data
# Copy JSON reference data
aws s3 cp . s3://your-raw-bucket/youtube/raw_statistics_reference_data/ \
--recursive --exclude "*" --include "*.json"
# Copy CSV files with regional partitioning
aws s3 cp CAvideos.csv s3://your-raw-bucket/youtube/raw_statistics/region=ca/
aws s3 cp USvideos.csv s3://your-raw-bucket/youtube/raw_statistics/region=us/5. Deploy Lambda & Glue Jobs
- Create Lambda function with
lambda function.pycode and AWS Data Wrangler layer - Set S3 trigger for JSON uploads
- Create Glue Crawler pointing to raw data
- Deploy Glue ETL job using the PySpark scripts
- Configure Athena workgroup and query results location
Optimization Techniques
Pushdown Predicates
Filters data at the source level, reducing data transfer and processing time.
Data Partitioning
Partitioned by region for query efficiency, enabling partition pruning in Athena.
Parquet Format
Columnar format for compression and fast queries — ~75% storage reduction vs CSV.
File Consolidation
Uses .coalesce(1) to reduce small file issues and improve query performance.
Use Cases
- Analyze trending YouTube videos across multiple regions
- Track video engagement metrics (views, likes, comments)
- Compare trending patterns between countries
- Identify popular categories and channels
- Time-series analysis of video trends